

tl;dr: Adblock Radio detects audio ads with machine-learning and Shazam-like techniques. The core engine is open source: use it in your radio product! You are welcome to join efforts to support more radios and podcasts.
Few people enjoy listening to ads on the radio. I built AdblockRadio.com to enable listeners to skip ads interruptions on their favorite webradios. The algorithm is open source and this article describes how it works.
Adblock Radio has been tested with real-world data from 60+ radios, across 7 countries. It is also compatible with podcasts. It works pretty well!
It is innovative compared to previous implementations, that could not be applied to all streams. A first one relies on webradio metadata, but only a small fraction of radios are compatible with this technique. Another one listens to known jingles, but in many cases the beginning and the end of ad breaks are not marked by a jingle.
In addition to detecting commercials, the proposed algorithm can also distinguish talk from music. So it can also be used to avoid chit-chat and listen to music only.
This is a report of personal work spanning over almost three years. I started Adblock Radio in the end of 2015, a few months after completing my PhD studies in fusion plasma physics. Soon after Adblock Radio gained some traction in 2016, I have received lawyer threats from French radio networks (more details below). I had to partially shut the website down, change its architecture, better understand the legal ramifications, etc. My vision today is that Adblock Radio will go much further with open innovation.
This article contains three parts that target different audiences. You can scroll down or click on their titles to navigate directly.
- Detecting ads: attempted strategies — for tech-savvy people, data scientists… It presents the different technical ways I have tested to detect advertisements, including speech recognition, acoustic fingerprinting and machine learning. I also discuss some paths for further work.
- Running Adblock Radio in the cloud is not recommended — for software developers but also for people interested in copyright law. It shows how difficult it is to find a satisfying intersection between technical and legal restrictions that apply to run Adblock Radio in cloud servers. For these reasons, it's better to run Adblock Radio on end users devices.
- You are welcome to integrate Adblock Radio in your radio player — for makers, product owners, UX designers, techies… I review ideas to integrate the open source algorithm in end user products, including cars, and highlight the need to get mispredictions flags from users to maintain the system. Finally, I give clues on how to design proper user interfaces. I expect a lot of feedback on this topic.

Detecting ads: attempted strategies
To block ads, it is first needed to detect them. My goal is to detect ads in an audio stream, without any cooperation from the radio companies. It is not an easy task. I have tried several approaches before getting good results.
1 - Low-hanging fruits (not working)
Loudness
A first idea is to check the loudness of the audio, because they are so noisy! Ads often rely on acoustic compression. This is an interesting criterion but it is not enough to discern ads from other content. For example, this strategy would work quite well for classical music stations where ads are most often louder. But it would not in pop music radios, where songs and announcements are as loud as ads. Moreover, some ads are quite on purpose, so they would not be detected.
Fixed-time blocking
Another idea is to consider that ads are broadcast at fixed times. This is true to some extent, but this lacks precision. For example, I have observed a morning show on a French station did not start exactly at the same time every morning, with variations of up to two minutes. Radio stations could easily defeat a block by time strategy by randomly shifting their programs by a few tens of seconds.
Metadata
An obvious solution would be to rely on webradio's ICY/Shoutcast metadata, that helps software like VLC display info about the stream. Unfortunately, this data is in most cases broken. It would be possible to fallback on the live stream info on radio websites (I developed a tool for this), but most often ads are not identified as is. In general, during ads, the website displays the name of the song or show that was broadcast before. One noteworthy exception to this rule is Jazz Radio where, at the time of writing, shows "La musique revient vite..." (music will be back soon) during ads. In conclusion, this strategy is not durable as radios can change that metadata very easily.
Human flagging
Finally, one could detect ads without any algorithm! One could simply ask some listeners to push a button when ads start or stop. Other listeners would benefit from this. This is the strategy behind the TV recorder TiVo Bolt. It offers to skip ads on a selection of channels at certain times. Its gives perfect results but does not scale well on thousands of radio stations.
A drawback is that it is difficult to bootstrap the system. A newly supported station may not have enough listeners at the same time for it to work correctly. Those listeners would get frustrated and leave.
Another difficulty is that radio stations have the incentive to send bogus flags to sabotage the system. This requires a system of moderation, user consensus or vote threshold.
Crowdsourcing is a good idea. I think it is even more durable if an algorithm does most of the work, leaving the minimum for people. That's what I have done.
2 - Speech recognition and lexical field analysis (failure)
Advertising is always about the same topics and lexical field: buying a car, getting supermarket coupons, subscribing to an insurance, etc. If audio can be converted to words, tools to fight email spam can be used to detect unwanted content. This has been my first path of research in late 2015, but it turns out I could not get speech recognition to work.
Being a newbie to speech processing, I started up by reading Huang's Spoken Language Processing, an excellent book, though now a bit dated. I got my hands dirty with CMU Sphinx, the best open source speech recognition toolkit at the time.
My first attempt gave very poor results and required heavy CPU computations. I used default parameters: standard French dictionary (list of possible words and corresponding phonemes), language model (probabilities of word sequences) and acoustic model (phoneme to waveform relationship).
I tried to improve the system, but in vain: recognition was still disappointing. I customized the dictionary and language model with a small dataset I had crafted for this purpose, using recordings split with a diarization tool. I also did MLLR to adapt the acoustic model to the broadcast station - Europe 1 (French) - I was studying.
I abandoned the idea to detect ads with speech recognition. This is probably a topic for experts. Note that this idea could be revisited. Much progress has been made in speech recognition since 2015. New open source tools have been published, such as Mozilla Deep Speech.
3 - Crowdsourced database of ads, detection with acoustic fingerprints (encouraging)
The first version of Adblock Radio in 2016 maintained a database of advertisements. It listened to the stream continuously, searching for ads. Results were really promising, but keeping the database up to date was challenging.
The search technique was acoustic fingerprinting, similar to what Shazam does on its servers when you want to identify a song. This kind of algorithm is commonly known as landmark. I adapted it to work on live streams and open-sourced it: adblockradio/stream-audio-fingerprint.
Fingerprinting is relevant to detect ads because ads are identically broadcast many times. For the same reason, it can also detect music. But this technique would not work for talk content because people never pronounce words the exact same way. Such talk detection may only happen for reruns at night, which does not interest us here. So, to build a fingerprints database, one should put ads and music (considered as "not an ad"), but inserting talk content is useless.
In more detail, audio fingerprinting is about converting some audio features into a series of numbers, called fingerprints. When many fingerprints match between live audio and an ad sample in a database, we can guess the radio is broadcasting ads. Some tuning is needed to have an optimal resolution and range in time and frequency. Different audio samples have to be correctly discriminated. But almost-identical audio should be matched, even if the audio encoding is different or if the radios apply different equalizer settings. Finally the amount of fingerprints should remain small, to not run out of computing resources.
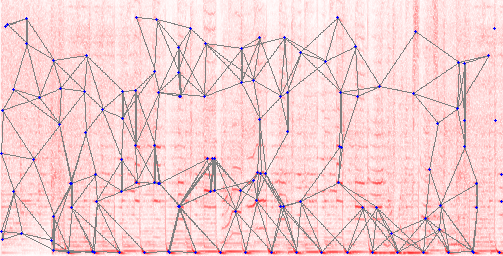
The classification was binary, classifying audio between ads and other content. The system gave almost only false negatives, i.e. it missed ads, and very rarely had false positives, i.e. marked good content as ad. Users could report undetected ads with a single click, giving an excellent user experience. The corresponding audio was automatically integrated in the DB. I moderated those actions a posteriori.
It was difficult to keep the database up to date as commercials change a lot. Similar ads are often broadcast in multiple slight variations. They are also renewed frequently, in some cases every few days. Some streams with not enough listeners were very poorly classified.
I investigated exciting strategies to automate some part of the work of listeners. Ads are identically broadcast many times every day. This can help identify them. I looked for maximally repeated sequences (MRS) in radio recordings. Other content is also repeated, such as songs and radio jingles. I sorted all sequences by length and looked at the results whose length was approximately 30 seconds, the typical length of ads. That way, I very often caught advertisements. But sometimes, I also got the refrain of songs (between different verses) or even recorded weather forecasts.
I found a way to discard most musical repeated sequences. I looked at the musical playlist of radios, downloaded the songs and integrated them in the database under a "not ad" label. Therefore more and more MRS candidates were actual ads. But still not all of them, so user actions were still needed.
Less manual work was necessary, but the I/O load on the servers had become problematic. In retrospect, the choice of SQLite for these read-write-intensive, time-critical database operations was probably not the best.
Fortunately, the algorithm had several seconds to determine if the sound was an ad or not. It is because webradios use an audio buffer, usually between 4 and 30 seconds, that is not immediately played on the end user device. It helps prevent audio cuts when the network is not reliable.
I used this buffer delay to post-process predictions, to make them more stable and context-aware. Just before the audio is played on the end user device, the algorithm looks at predictions results that are still in the buffer, as well as older ones that have already been played. It prunes dubious data points with few fingerprint matches, introducing a hysteresis behavior. It also does a weighted time average to smooth out temporary glitches.

4 - Acoustic classification between ads, talk and music with machine learning (almost there!)
The next version of the algorithm analyzed the acoustic content of radio broadcasts: low to high-pitched sounds, and their variations in time. New unknown ads were detected almost as well as the old ones used for tuning, just because they are as noisy and catchy. This is a more sophisticated method to monitor the audio loudness (see previous discussion).
For this, I used machine learning tools, more precisely the Keras library wired to Tensorflow. It gave very good results while using few computational resources. It stayed in production for more than a year, from early 2017 to mid 2018. Distinction between talk and music turned out to be reachable, so the classification became more precise, from ad /not ad to ads / talk / music.
Let's dive into details. I converted sound in a 2D map, giving the intensity of the sound as a function of frequency and time (on a scale of about four seconds). This map was conceptually similar to the red one in the fingerprinting paragraph. The main difference is that instead of classical Fourier spectra, I used the Mel-frequency cepstral coefficients that are common in speech recognition contexts.
Consecutive maps, at different timestamps, were then analyzed like pictures in a movie with a LSTM (long short-term memory) recurrent neural network. Each map was analyzed independently from the other (stateless RNN) but maps overlapped each other. Maps were 4-second long and there was a new map every second. The final output for each map was a softmax vector, such as ad: 72%, talk: 11%, music 17%. Those predictions were then post-processed in a similar way than described before with the acoustic fingerprinting technique.
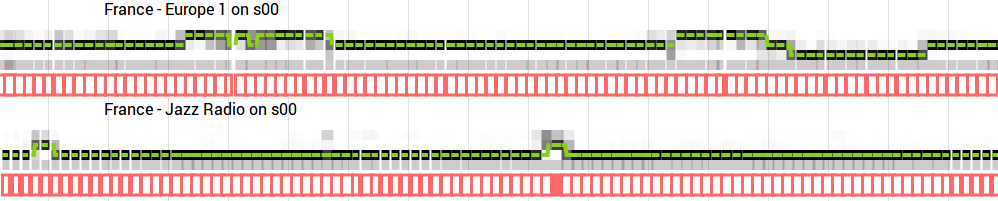
Initially, I trained the neural network with a very small dataset. I developed a UI tool (see figure above) to visualize predictions versus time and could add more data to train models with better performance. At the time of writing, the training dataset contains about ten days of audio: 66 hours of ads, 96 of talk and 73 of music.
Despite the good behaviour, the precision of the classification reached a plateau a bit below user expectations (see Future improvements below). At training, categorical accuracy was about 95%. The remaining mispredictions made the listener experience subpar.
Note for data scientists: it is common practice to present formal performance measures, by splitting the dataset into training and testing subsets. I think it is not meaningful to do it here, because the dataset has been built incrementally with data that was confusing to earlier models. It means the dataset contains more pathological data than the average radio broadcast and that the accuracy would be underestimated. A separate work to measure the real-world performance would be needed. An operator could label continuous segments of regular audio records, as test data, and calculate precision and recall against it. Doing this on a regular basis would enable to monitor the health of the filters.
Predictions became between ad, talk and music brought more flexibility for listeners. But such classification made the user interfaces more complex and the user reports became more difficult to handle. If a flag indicates that some content is not music, is it an ad or is is talk? This required a priori moderation.
To improve the quality of detection even further, I designed the last version of Adblock Radio, which is an incremental improvement of this strategy.
5 - Combination of acoustic classification and fingerprint matching (win!)
The best performing algorithm I have built is available on Github. For improved reliability, it combines concepts from the two previous attempts: acoustic classification and audio database.
The machine learning predictor, if properly trained, provides correct classifications on most original content, but it fails in some situations (see below in Future improvements section). The role of the fingerprint matching module is to alleviate the errors of the machine learning module.
Not all known training data is put in the database of the fingerprint module. Only the small subset of the database that is mispredicted by the machine learning predictor is inserted. I call it the hotlist database. Its small size helps reduce the overall error rate while keeping computations cheap.
On a regular laptop CPU, the whole algorithm runs at 5-10X for files and at 10-20% usage for live stream.
Future improvements
Some kinds of content are still problematic
Detection is not perfect for some specific kinds of audio content:
- hip-hop music, easily mispredicted as advertisements. Workaround is to add tracks to the hotlist, but that's a lot of music to whitelist. A more general neural network could be designed, but maybe at the cost of performance.
- ads for music albums, often mispredicted as music. But blocking them with fingerprints would lead to false positive detection when the real song is broadcast. Can be solved by doing a stronger context analysis, but is hard to solve for live streams where future further than a few seconds of buffer is unknown.
- advertisements for talk shows, mispredicted as talk. This is litigious, because those are both talk and ad at the same time. It highlights a limit of the ad / talk / music classification. For fingerprints classification, I have used for a while an ad_self class, containing announcements for shows on the same station, but stopped doing it with the machine learning algorithm. It may be wise to recreate that class. Alternatively, context could be better analyzed to identify this as ads.
- native advertisements, where the regular speaker reads sponsored content. This is quite unusual on radios, though more common in podcasts. The logical next step for this would be to use speech recognition software.
Markov chains for a more stable post-processing
Stability of the post-processing could be improved. Currently, it only uses confidence thresholds. When below the threshold, it uses the last confident prediction. Thus the system sometimes persists in error.
Cycles of ads, talk and music are fairly repetitive for each radio streams. For example, an ad break commonly lasts a few minutes. For each period of time in an ad break, it would be possible to calculate a probability of transition to another state (talk or music). That probability would help better interpret noisy predictions of the algorithm: is this just a short segment of music in an ad or is the ad break finished? In this topic, Hidden Markov Models are a good direction to look at.
Analog radio is not supported yet
Analog signals (FM) have not been tested and are not currently supported. Analog noise might void the techniques used here. Filters and/or noise-resistant fingerprinting algorithms may be needed. Work on this topic could broaden the use cases of this project. However, in the future, radio will be more significantly consumed with noise-free technologies such as DAB and webradios.
Running Adblock Radio in the cloud is not recommended
Adblock Radio should ideally be run on the end user device. But it is in vogue to do the computations in the cloud and to serve the results to the listeners. Moreover, it would be a great business idea! Adblock Radio has tested two options to design architecture with this paradigm. First-hand experience shows it is not an ideal solution, for technical and legal reasons.
Option #1 - Server rebroadcasts audio
The analysis server can transmit audio content to listeners, with ad/talk/music tags. This has been briefly tested in 2016. This leads to legal issues as relaying a stream could be considered as counterfeiting and/or copyright infringement (disclaimer: IANAL). Also this scales poorly because now you are a CDN and have to bear the costs.
For the anecdote, on a Sunday while I was at a family meeting, Adblock Radio has got some virality and subsequently a hug of death. Fun fact: a few days later, France Inter, a major French public radio station, advertised Adblock Radio at a high audience time (though, without naming it). This surprising editorial choice may be put in perspective with the fact that regulators chose in 2016 to loosen restrictions for ads broadcast on public radio stations, contributing to a poor climate between the staff of Radio France and its direction.
A few weeks later, I received lawyer threats from French private radio network Les Indés Radios, on supposed grounds of copyright and trademark infringements. Lacking the financial resources to seriously defend myself, it forced me to remove some streams from the site, partially shut down the site and change the architecture of the system. At the time, that radio group declined to start a collaboration to find a middle ground. Ever since, I could detect by traffic analysis that they have kept monitoring my website (sometimes with pseudonymous accounts) and consulted their lawyers. What an honor! Retrospectively, they successfully bought time, but nothing more. Hi Indés guys! Hope you enjoy reading this! xoxoxo.

Option #2 – Server rebroadcasts audio, but it's private copy
An option would be to consider that analysis and relaying of the cleaned audio stream is an operation for a specific individual. Such a system could land in legal exceptions of the right to do private copies of your own media. If the server is managed by the end user, this is probably fine, as long as the original source is legal and officially available in your area. For more information about this, please refer to discussions about Station Ripper [FR] and VCast [FR]. But end users are rarely tech-savvy enough to rent and install a server to do this.
It is very tempting to have the server managed by a third party, but this leads to legal trouble as, when the operator doing the copy and the end user are not the same person, legal restrictions apply, at least in France. French Internet service Wizzgo [FR] got smashed by this rule in 2008. More recently, in the USA, TV service Aereo got sued into oblivion even if it took the precaution to use a separate tuner for each of its clients (!).
Current actor Molotov.TV [FR] is struggling against the attacks of rights holders that want restrictions on features [FR], despite the considerable influence of its cofounders. It is required to pay a private copy levy to an official organization [FR]. The amount is determined by rather opaque calculations [FR] and is increasing [FR] year after year, reaching a few tens of euro cents per user and per month. That fee has become so high that Molotov.TV recently removed features of its service for free users [FR]. (Note: I warmly thank the journalists of French website NextINpact for their very good coverage on this topic).
Paying is not enough: law requires actors such as Molotov.TV to sign agreements [FR] on features with the companies holding the copyrights. Good luck reaching an agreement with radio companies if you ostensibly cut their ads.
Option #3 - Server only sends metadata
The other option is to have both the user and the server listen to the same webradio at the same time. The server analyzes the audio and sends to the user classification metadata (ad/talk/music), but no audio content. This architecture is in production on adblockradio.com since 2017. It relies on the CDN of radios, so there is no cost or availability requirements to bear regarding the broadcast of audio.
This architecture has the benefit to clear legal concerns about author's rights (disclaimer: I am not a lawyer). However, there may still be some uncertainty about trademark laws. Recently (october 2018), the radio network behind Skyrock has requested the removal of content on such supposed grounds.

Legal considerations apart, a technical issue is that there is no way to be sure synchronization between audio and metadata will be correct. In most cases, it works well, with a sync gap of less than two seconds. But some radios have weird/malicious CDNs or have introduced dynamic advertising in their streams. This means that streams between the server and the clients can become significantly different. For example, lags of about 20s have been observed for Radio FG and up to 45s for Jazz Radio. This leads to a frustrating experience for listeners.
Synchronization can be brutally enforced by comparing data chunks between the server and the user. Unfortunately, this does not work in web browsers, because most webradios CDNs have not enabled CORS headers. It means that JavaScript in browser will not be able to read the audio content to compare it. Standalone bundles (e.g. Electron), Flash modules (duh) or web extensions would be needed, but this seems slightly overkill.
You are welcome to integrate Adblock Radio in your radio player
This project is not intended to be handled by end-users. It is meant to be integrated in mass market products. You are welcome to do it!
Developers have two options to integrate Adblock Radio. The first one, using the SDK, simply fetches live metadata from adblockradio.com servers. It is not the ideal solution for reasons detailed above (legal & sync issues). The better bet is to run the full analysis algorithm.
Software
- mobile apps for webradios and podcasts. Keras models should be converted to native Tensorflow ones, and the Keras + Tensorflow library could be replaced with Tensorflow Mobile for Android and iOS. Node.JS routines could be integrated with this React Native plugin or less probably with Termux.
- browser extensions, with Tensorflow JS and SQL.js. The extension could take control of the volume knob on popular webradios catalogs such as TuneIn or Radio.de. I already did work on this. It was funny to reverse engineer the JavaScript players to control them. Depending on how you implement this, be aware of the synchronization issues detailed above.
Hardware
- digital alarm-clocks and hobbyist projects, as long as enough computation power and network are available. Platforms as small as Raspberry Pi Zero/A/B should be enough for single stream analysis, though RPi 3B/3B+ is recommended to monitor several streams in parallel. Tensorflow is available on Raspbian.
- connected speakers, such as Sonos. The algorithm itself will not run on Sonos hardware, so, if not done in the cloud, a separate hardware device on the same local network could do it (such as a Raspberry). Great idea for a crowdfunding campaign.
Using Adblock Radio in a car
Car is one of the most frequent situations where people listen to the radio. Users do need Adblock Radio there. It is also a context where implementing Adblock Radio is not straightforward. The algorithm needs updates to efficiently filter new ads, therefore it needs a network connection. I present three possible concepts of car products featuring Adblock Radio.
- App compatible with infotainment systems of modern cars – The easiest way to transmit data in a car device is probably through a smartphone's Internet access. A smartphone can be used alone with a mobile app, streaming webradios, with it's audio out connected to the car's AUX or Bluetooth audio in. It could also be integrated with the car's infotainment system, in the spirit of Apple Car Play, Android Auto and MirrorLink. It would be fantastic to listen to terrestrial radio (FM, DAB). But work is needed to identify in what exact configurations Adblock Radio can gain access to the audio output of the radio tuner and, at the same time, control the tuner (volume, channel).
- Universal hardware adapter, dedicated user interface – It is also possible to develop custom hardware, similar to existing DAB adapters for cars. These devices tune to radio stations and transmit the audio data to the car system through an AUX jack connection or through an unused FM channel, like those old iPod FM adapters do. Network access could again rely on a smartphone through a Bluetooth connection. Alternate solutions could be considered, like Sigfox and LoRa, if communication bitrate and price are found to be compatible. One should design a dedicated user interface, separate from the car's head unit. This may be too expensive to be viable.
- Minimalist device that hacks FM reception – For the convenience of using the main car radio interface instead of that of a small device, the small device could be headless and take control of the tuner when needed. There is no interface for that, being standard and easily connectable at the same time. A good candidate would have been the steering wheels controls, but they cannot be easily adapted by end users. So we need to hack into the system.
The headless device would have a FM tuner and would get to know which station is listened in the car with a microphone (doing cross-correlation). When ads are detected, it would emit bogus RDS data (such as traffic announcements) to cheat the car tuner into changing station during ads. It could also emit blank audio on the same FM frequency to turn the volume down.
The interface of such device would be very simple, with just a few knobs. So it would be cheaper than the full-featured car adapter. However it is unclear if this would work reliably as, without a license, the emitting power is strictly limited by law. Finally it is unknown if such strategy could be adapted to work with digital DAB streams.
If the technique can be worked out with a cheap bill of materials, a product offering Adblock Radio in cars would very likely be a commercial success. Moreover it is crowdfunding-friendly.
Adblock Radio needs reports of mispredictions from listeners and help to process them
When integrating Adblock Radio in a product, please give the user a way to give negative feedback on the classification. Mispredictions should promptly be reported to me so that I can update ML models and hotlist databases accordingly.
Reports are manually reviewed: it is enough to provide the name of the radio(s) and a timestamp at which the problem happened. For a given selection of radios, one report every few minutes is enough. A mechanism to send reports is included in the library.
Processing reports is a burden. In addition to server costs, this is why I have not added more radios to adblockradio.com. Help on this is needed, by listening to audio tracks and classifying them on a dedicated web administration interface. This can make more radios available, as well as bring support for native podcasts. If you are ready to help, please register here and watch this Github repo where discussion about supported streams will take place.
What to replace ads with – a UX challenge
Skipping ads in a podcast is trivial in terms of user experience: it is like skipping a part of a song. Unfortunately, it is not as simple for radio. Broadcasts are linear and for live content, fast-forwarding is not an option!
The current adblockradio.com service offers three options to the users when an ad is to be filtered:
- turning the volume down
- tuning to another radio, tuning back when ads are over. This is relevant when the user listens to a radio show. During ads, it fallbacks temporarily on a musical station.
- permanently tuning to another radio. This is useful when listening to several musical stations.
I made efforts to give the best possible user experience, but it is still complex. Not as straightforward as a regular radio and not as simple as adblockers on computers, that are amazingly install and forget. I really count on the community to brainstorm on this topic.


There is another way to consume content that I find interesting. For legal reasons discussed above, I could not implement it on adblockradio.com. I have built instead a standalone desktop player (also available on Github), inspired by the digital video recorders capabilities. Users start listening with a time-shifting of about 10 minutes (i.e. if they start listening at 7.30AM, they listen to the audio broadcast at 7.20AM). Each time an ad break happens, they fast-forward and enjoy their program without interruptions. Given the typical amount of ads, a time-shift of 10 minutes gives the ability to listen without breaks for an hour or two. If it were a mobile app, it would be long enough to commute to work.
When the user turns the device on, audio from ten minutes before has to be served. How to do this in a mobility context, with energy and data volume constraints? Note that law prevents unlicensed third parties (in the cloud) to serve radio recordings.
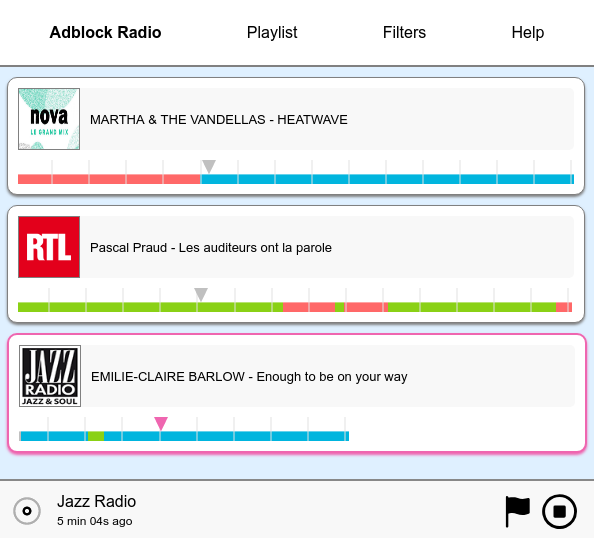
In the long term, the solution is likely to consume broadcast content on-demand and to completely customize it according to the tastes of each listener. Mark radio shows as favorites, choose musical tastes, insert podcasts, etc. The optimal experience would be, in my opinion, to offer Spotify-like features on live content that cannot wait to be downloaded as a podcast: sport events, news reports, weather forecast, live music, etc. It could even be the foundation of an alternate business model for radios.
Conclusion
The technical solution to detect ads in radio streams and podcasts is more complex than I wish it were. Its models need to be periodically updated to account for new advertisements, which means the system is to be used in devices connected to the Internet, such as smartphones and WiFi radios. It cannot yet be used in regular offline Hertzian-only radios (FM, DAB+). Fortunately, uses of radio are changing with ubiquitous mobile data carriers, so that the use of this algorithm will plausibly be easier in the future.
You can help Adblock Radio go further.
- As a radio listener: go to adblockradio.com/player, listen to the radio and flag prediction errors so that the algorithm can learn. Are your favorite stations missing? No problem, go to github.com/adblockradio/available-models/ and submit your request.
- As a developer: go to github.com/adblockradio/adblockradio/, run the demo, tinker and join the discussion. Check out also the standalone desktop demo player in Electron at github.com/adblockradio/buffer-player.
- As a product manager: get in touch if you want to integrate Adblock Radio in your product. I will be glad to help.
In the future, audio ads will only be distant memories! Thank you for reading.
Spread the word!
This article got featured on:
- Reddit's r/programming
- Hacker News (front page #5)
- Gigazine (Japan)
- HABR (Russia, #1 daily top)